") 近似算法及對某些標準問題的適用性
近似算法及對某些標準問題的適用性

新冠大流行給世界帶?來了巨大的改變,全球科學(xué)家和研究人員在研制有效的疫苗。他們正在做的就是從廣闊的樣本空間中近似地收緊可能性范圍,并盡力得到一些有效解。近似在我們的生活中發(fā)揮了重要作用。以在線食品配送為例,我們經(jīng)常從網(wǎng)上訂購食物,享受快速送達的服務(wù)。但你想過這些 app 后端運行的什么算法讓快遞員在更短時間內(nèi)抵達目的地嗎?答案是近似算法。這類問題就是「旅行商問題」。
食品配送:旅行商問題的現(xiàn)實應(yīng)用。本文將介紹近似算法及其對某些標準問題的適用性,以及哪些因素會影響到特定算法的選擇。什么是近似算法?近似算法是一種處理優(yōu)化問題 NP 完全性的方式,它無法確保最優(yōu)解。近似算法的目標是在多項式時間內(nèi)盡可能地接近最優(yōu)值。它雖然無法給出精確最優(yōu)解,但可以將問題收斂到最終解的近似值。其目標滿足以下三個關(guān)鍵特性:
能夠在多項式時間內(nèi)高效運行;
能夠給出最優(yōu)解;
對于每個問題實例均有效。
背景數(shù)學(xué)表達式的評估常伴隨常量、變量分析和方程的階,可用于衡量近似的復(fù)雜度。此類評估將問題分解為 P 和 NP 難問題。P 問題和 NP 問題的策略P 問題是指可以在多項式時間內(nèi)求解的問題。NP 表示不確定性多項式時間(nondeterministic polynomial time),NP 問題是指在多項式時間內(nèi)近似驗證答案的問題。但目前人們發(fā)現(xiàn),很多此類問題需要指數(shù)時間才能求解。
P 和 NP 策略。真正的爭論在于 P=NP 還是 P≠NP。之前的一些研究證明這兩種都是對的。如果一個問題是多項式次方,則存在多個最優(yōu)算法。因此,在 NP 完全問題中,存在兩種方法找到近優(yōu)解,然后選擇最適合的算法。如果輸入的大小比較小,則具備指數(shù)運行時間的算法可能會比較適合。其次,通過用近似算法替代確定性算法,我們?nèi)匀荒軌蛟诙囗検綍r間內(nèi)找到近優(yōu)解。近似算法的復(fù)雜度可以從輸入大小和近似因子中推斷出來。接下來,我們通過一些示例,深入探索這些算法如何應(yīng)用到現(xiàn)實問題中。分區(qū)問題(Partition Problem)在計算機科學(xué)領(lǐng)域,該問題的定義是:給定多重正整數(shù)集 X,它可以被分割為兩個元素之和相等的子集 X1 和 X2,即每個子集的數(shù)值之和與另一個子集相等。
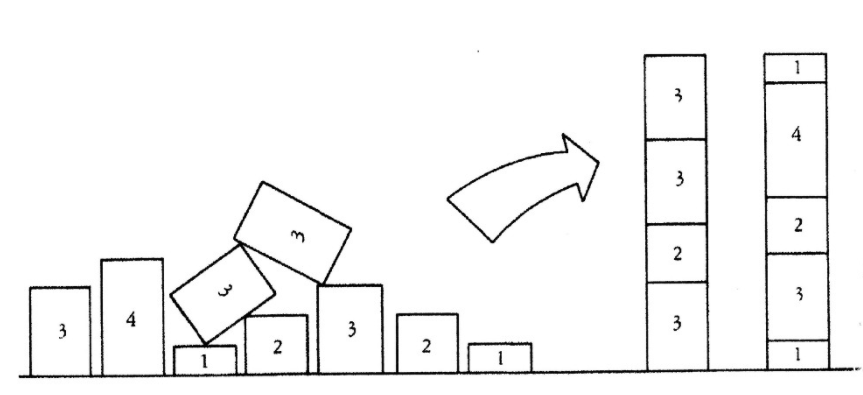
例如,X={3,4,1,3,3,2,3,2,1} 可以被分割為 X1={3,3,2,3} 和 X2={4,2,3,1,1},二者的數(shù)值之和都是 11。類似地,X={1,3,1,2,1,2} 可以被分成 X1={2,1,1,1} 和 X2={3,2},兩個子集的數(shù)值之和都是 5。有趣的是,這不是唯一解。X1={1,3,1} 和 X2={2,1,2} 的數(shù)值之和也為 5,這表明存在多個可能的子集。這就是 NP 完全問題,存在偽多項式時間動態(tài)規(guī)劃解,可獲得該問題的近優(yōu)解。方法和決定步驟現(xiàn)在,我們開始分析這個問題,把它分解成數(shù)個單獨的標準問題。這里,我們想要找出多重集的元素之和相等的子集,那么該問題就可以分解成以下兩個問題:
子集和問題:子集 X 的元素之和等于數(shù)字 W。
多路數(shù)字分割:給定整數(shù)參數(shù) W,確定如何將 X 分割成 W 個等額子集。
近似算法如上所述,將分區(qū)問題分解為多路分割與子集和問題后,我們就可以考慮為這些問題而開發(fā)的算法,包括:貪婪數(shù)字分割(Greedy number Partitioning)該算法循環(huán)遍歷所有數(shù)字,將每個數(shù)字分配給總和最小的子集。如果數(shù)字未以排序方式排列,則其運行時復(fù)雜度為 O(n),近似率約為 3/2。其 Python 偽代碼如下:
def find_partition(numbers):"""Separate the available numbers into two eqal sum series.Args:numbers: collection of numbers, for example list of integers.Returns:Two lists of numbers."""X = []Y = []sum_X = 0sum_Y = 0for n in sorted(numbers, reverse=True):if sum_X < sum_Y:X.append(n)sum_X = sum_X + nelse:Y.append(n)sum_Y = sum_Y + nreturn (X, Y)
將數(shù)字排序,則運行時復(fù)雜度增加到 O(n logn),近似率增加到 7/6。如果數(shù)字在 [0,1] 范圍內(nèi)均勻分布,則近似率約為 1 + O(log logn/n)。
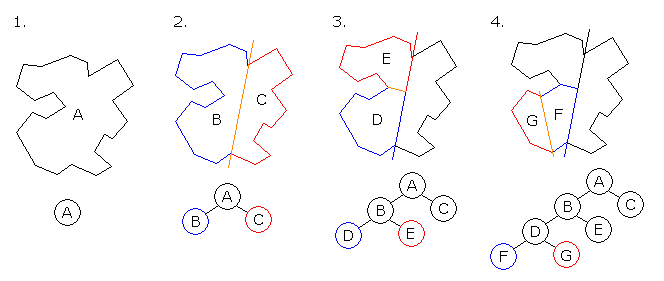
分區(qū)問題圖示。上圖用二叉樹的形式展示所有分區(qū)。樹的根部表示集合中的最大數(shù),每一級對應(yīng)輸入數(shù)字,每個獨立分支對應(yīng)不同的子集。遍歷這些集合需要深度優(yōu)先遍歷(depth-first traversal),所需的空間復(fù)雜度為 O(n),時間復(fù)雜度為 O(2^n)。適用性:該算法可以根據(jù)情況進行修改,以便改善運行時復(fù)雜度。每一級的首要目標是構(gòu)建一個分支,將當前數(shù)字分配給總和最小的子集。首先通過貪婪數(shù)字分割找出總和,然后切換到優(yōu)化,得到全多項式時間近似解。Karmarkar-Karp 算法Karmarkar-Karp 算法指以降序方式排列數(shù)字的最大差分方法,該方法將差值替換掉原來的數(shù)字不斷放進集合中。其 Java 偽代碼實現(xiàn)如下:
int karmarkarKarpPartition(int[] baseArr) {// create max heapPriorityQueue heap = new PriorityQueue(baseArr.length, REVERSE_INT_CMP);for (int value : baseArr) {heap.add(value);}while (heap.size() > 1) {int val1 = heap.poll();int val2 = heap.poll();heap.add(val1 - val2);}return heap.poll();}
該算法包含輸入集 S 和參數(shù) k。將 S 分割成 k 個子集,使這些子集中的數(shù)字總和相等,從而構(gòu)建期望輸出。該算法包含如下關(guān)鍵步驟:
以降序方式排列數(shù)字;
用差值替換掉原來的數(shù)字,直到只有一個數(shù)字;
采用回溯算法,完成分區(qū)。
適用性:該算法通過構(gòu)建二叉樹來假設(shè)分區(qū)。每一級表示一對數(shù)字,左側(cè)的分支表示用差值替換數(shù)字,右側(cè)的分支表示將差值放置在同一個子集中。該算法先通過最大差分求得解,然后繼續(xù)尋找更好的近似解。它所需的空間復(fù)雜度為 O(n),但最糟糕的情況下所需的時間復(fù)雜度可能會達到 O(2^n)。裝箱問題裝箱問題有多種現(xiàn)實應(yīng)用。例如,如何從根本上改善印度的垃圾管理系統(tǒng)。這個問題就可以通過裝箱問題來解決,幫助當局決定 x 量的垃圾需要多少個垃圾箱。
在計算機科學(xué)領(lǐng)域中,該問題可用于多種內(nèi)存管理技術(shù)。在該算法中,我們可以通過去除冗余和最小化空間浪費來包裝不同形狀和大小的對象。例如:給定一個包含 n 個項的集合,每個項的大小分別為 s1,s2,。.,sn (0《=si《=1, 1《=i《=n),如何將它們裝進最少數(shù)量的箱子?經(jīng)典方法:1. 鄰近適應(yīng)算法 (Next Fit):查看當前項是否適合當前箱子。如果適合,則將物品放置在箱子里,否則開啟一個新的箱子。我們來看一個示例:項是 0.5, 0.7, 0.5, 0.2, 0.4, 0.2, 0.5, 0.1, 0.6,箱子大小均為 1。
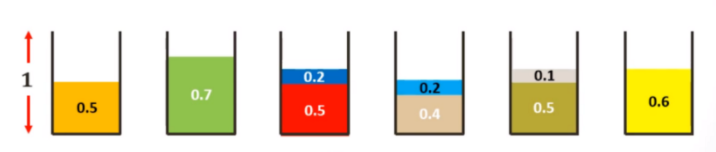
基于鄰近適應(yīng)算法的裝箱解決方案(M = 箱子總數(shù) = 6)。2. 最先匹配法 (First Fit):按順序瀏覽箱子,在第一個箱中放置新的項,直到放不下再啟用新的箱子。我們來看一個示例:項是 0.5, 0.7, 0.5, 0.2, 0.4, 0.2, 0.5, 0.1, 0.6,箱子的大小均為 1。
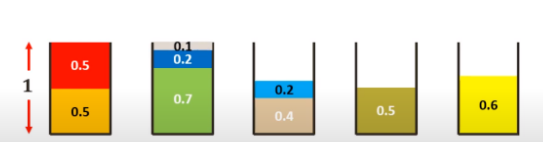
基于最先匹配法的裝箱解決方案(M = 箱子總數(shù) = 5)。3. 最優(yōu)匹配法 (Best Fit):按順序瀏覽箱子,將每一個新的項放在最適合的箱子里。如果不適合,則創(chuàng)建一個新的箱子。我們來看一個示例:項是 0.5, 0.7, 0.5, 0.2, 0.4, 0.2, 0.5, 0.1, 0.6,箱子的大小均為 1。
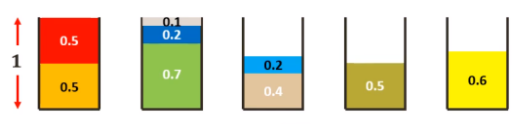
基于最優(yōu)匹配法的裝箱解決方案(M = 箱子總數(shù) = 5)。該方法的輸出與最先匹配法相同,但該方法的優(yōu)點是實現(xiàn)速度比 FFD 快,即時間復(fù)雜度為 O(nlogn)。自然方法:如果我們提前知道所有項的大小,那么自然的解決方案就是首先按照從大到小排序,然后應(yīng)用以下啟發(fā)式方法:
最先匹配遞減法
最優(yōu)匹配遞減法
假設(shè)有相同的示例 0.7, 0.6, 0.5, 0.5, 0.5, 0.4, 0.2, 0.2, 0.1,則排序為 0.7, 0.6, 0.5, 0.5, 0.5, 0.4, 0.2, 0.2, 0.1。
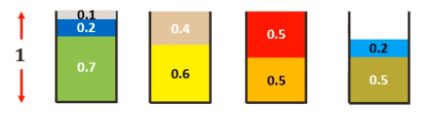
優(yōu)化方法(M = 箱子總數(shù) = 4)。
審核編輯:郭婷
-
計算機
+關(guān)注
關(guān)注
19文章
7807瀏覽量
93202 -
python
+關(guān)注
關(guān)注
57文章
4876瀏覽量
90030
原文標題:什么是近似算法?它適用于哪些問題?這篇文章給你答案
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
鋁電解電容在高頻電路適用性如何選?

電能質(zhì)量在線監(jiān)測裝置精度等級劃分標準適用于哪些場景?

Leadway電機方案的適用性
IEC 62368標準適用于哪些產(chǎn)品

查找表與多項式近似算法實現(xiàn)初等函數(shù)
加密算法的應(yīng)用
全面解析HT97226耳機放大器:性能、適用性

哪些數(shù)字濾波算法適用于電能質(zhì)量在線監(jiān)測裝置?
如何判斷電能質(zhì)量在線監(jiān)測裝置認證標準的有效性?

EN 62196標準對電動汽車充電插頭和接口的適用范圍和安全要求

步入式高低溫試驗室支持哪些測試標準?一次性梳理清楚




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論