 利用RAPIDS機器學習實現Transformer的微調
利用RAPIDS機器學習實現Transformer的微調

近年來, transformers 已成為一種強大的深度神經網絡體系結構,已被證明在許多應用領域,如 自然語言處理 ( NLP )和 computer vision ,都超過了最先進的水平。
這篇文章揭示了在微調變壓器時,如何以最快的訓練時間獲得最大的精度。我們展示了 RAPIDS Machine Learning 庫中的 cuML 支持向量機( SVM )算法如何顯著加快這一過程。 GPU 上的 CuML SVM 比基于 CPU 的實現快 500 倍。 這種方法使用支持向量機磁頭,而不是傳統的 多層感知器( MLP )頭 ,因此可以精確輕松地進行微調。
什么是微調?為什么需要微調?
transformer 是一個 deep learning 模型,由許多多頭、自我關注和前饋完全連接的層組成。它主要用于序列到序列任務,包括 NLP 任務,如機器翻譯和問答,以及計算機視覺任務,如目標檢測等。
從頭開始訓練 transformer 是一個計算密集型過程,通常需要幾天甚至幾周的時間。在實踐中,微調是將預訓練的變壓器應用于新任務的最有效方法,從而減少培訓時間。
用于微調變壓器的 MLP 磁頭
如圖 1 所示,變壓器有兩個不同的組件:
主干,包含多個自我注意塊和前饋層。
頭部,對分類或回歸任務進行最終預測。
在微調過程中, transformer 的主干網絡被凍結,而只有輕型頭部模塊接受新任務的培訓。 head 模塊最常見的選擇是 multi-layer perceptron ( MLP ),用于分類和回歸任務。

圖 1 。以 cuML-SVM 為磁頭加速變壓器的微調
事實證明,實現和調整 MLP 可能比看起來要困難得多。為什么?
有多個超參數需要調整: 層數、輟率、學習率、正則化、優化器類型等。選擇要調整的超參數取決于您試圖解決的問題。例如,輟 和 batchnorm 等標準技術可能會導致 回歸問題的性能退化 。
必須采取更多措施防止過度安裝。 變壓器的輸出通常是一個長的嵌入向量,長度從數百到數千不等。當訓練數據大小不夠大時,過度擬合很常見。
執行時間方面的性能通常不會得到優化。 用戶必須為數據處理和培訓編寫樣板代碼。批量生成和從 CPU 到 GPU 的數據移動也可能成為性能瓶頸。
SVM 磁頭用于變壓器微調的優勢
支持向量機 (支持向量機)是最受歡迎的監督學習方法之一,當存在有意義的預測性特征時,支持向量機是最有效的。由于 SVM 對過度擬合的魯棒性,對于高維數據尤其如此。
然而,出于以下幾個原因,數據科學家有時不愿嘗試支持向量機:
它需要手工特征工程,這可能很難實現。
傳統上,支持向量機速度較慢。
RAPIDS cuML 通過提供 在 GPU 上的加速比高達 500 倍 重新喚起了人們對重溫這一經典模型的興趣。有了 RAPIDS cuML ,支持向量機在數據科學界再次流行起來。
例如, RAPIDS cuML SVM 筆記本電腦已在多個 Kaggle 比賽中頻繁使用:
TReNDS Neuroimaging by Ahmet Erdem
CommonLit Readability by Chris Deotte
PetFinder by Chris Deotte
由于 transformers 已經學會了以長嵌入向量的形式提取有意義的表示, cuML SVM 是頭部分類器或回歸器的理想候選。
與 MLP 頭相比, cuML SVM 具有以下優勢:
容易調整。 在實踐中,我們發現在大多數情況下,僅調整一個參數 C 就足以支持 SVM。
速度 。在 GPU 上處理之前, cuML 將所有數據一次性移動到 GPU 。
多樣化 。支持向量機的預測與 MLP 預測在統計上不同,這使得它在集合中非常有用。
Simple API. cuML SVM API 提供 scikit-learn 風格的擬合和預測功能。
案例研究: PetFinder 。我的掌門人競賽
提出的帶有 SVM 磁頭的微調方法適用于 NLP 和 計算機視覺任務 。為了證明這一點,我們研究了 寵物搜尋者。我的掌門人競賽 ,這是一個 Kaggle 數據科學競賽,它根據寵物的照片預測了它們的受歡迎程度。
該項目使用的數據集由 10000 張手動標記的圖像組成,每個圖像都有一個我們想要預測的目標 pawpularity 。當 pawpularity 值在 0 到 100 之間時,我們使用回歸來解決這個問題。
由于只有 10000 個標記圖像,因此訓練深層神經網絡以從零開始獲得高精度是不切實際的。相反,我們通過使用預訓練的 swin transformer 主干,然后用標記的 pet 圖像對其進行微調來實現這一點。
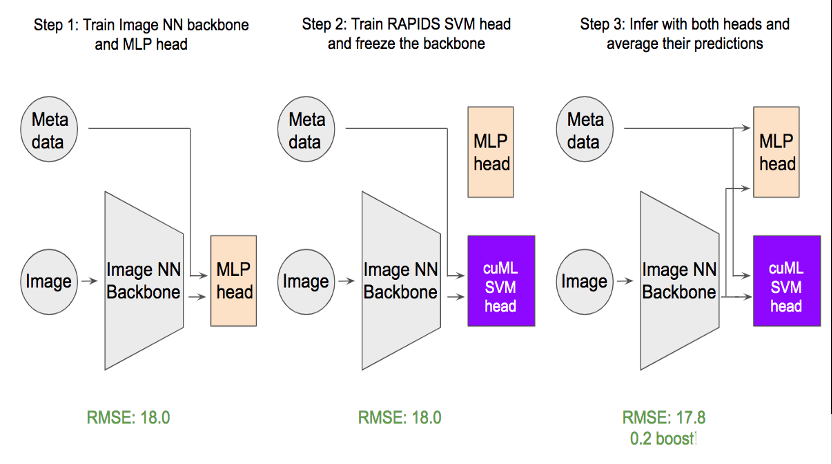
圖 2 。如何使用 cuML SVM 頭進行微調。
如圖 2 所示,我們的方法需要三個步驟:
首先,將使用 MLP 的回歸頭添加到主干 swin 變壓器,并對主干和回歸頭進行微調。一個有趣的發現是,二進制交叉熵損失優于常見的均方誤差損失( MSE ) 由于目標的分布 。
接下來,主干被凍結, MLP 頭被替換為 cuML SVM 頭。然后用常規的 MSE 損失對 SVM 頭進行訓練。
為了獲得最佳預測精度,我們對 MLP 頭和 SVM 頭進行了平均。求值度量根意味著平方誤差從 18 優化到 17.8 ,這對該數據集非常重要。
值得注意的是,第 1 步和第 3 步是可選的,在這里實施的目的是優化模型在本次比賽中的得分。僅步驟 2 是微調最常見的場景。因此,我們在步驟 2 測量了運行時間,并比較了三個選項: cuML SVM ( GPU )、 sklearn SVM ( CPU )和 PyTorchMLP ( GPU )。結果如圖 3 所示。
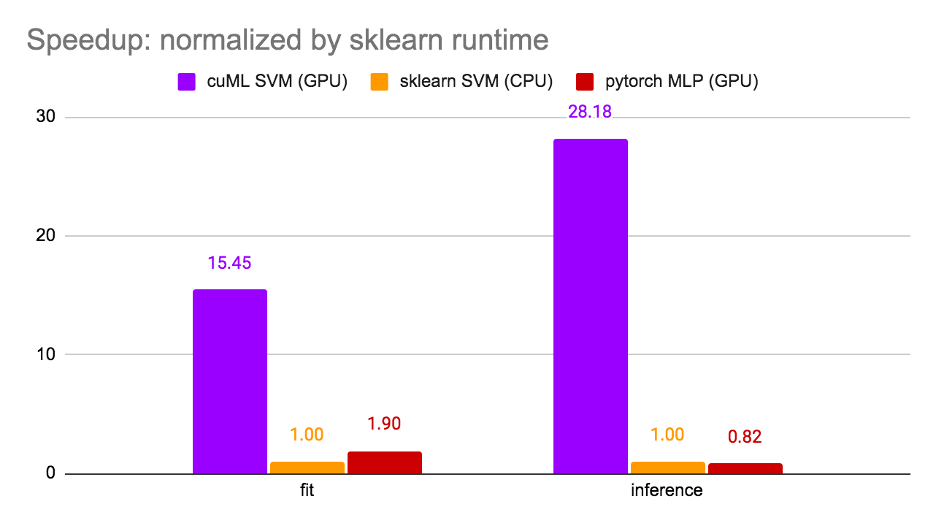
圖 3 。運行時比較
使用 sklearn SVM 對運行時間進行歸一化, cuML SVM 實現了 15 倍的訓練加速比和 28.18 倍的推理加速比。值得注意的是,由于 GPU 利用率高, cuML SVM 比 PyTorch MLP 更快。 筆記本可以在 Kaggle 上找到。
Transformer 微調的關鍵要點
Transformer 是革命性的深度學習模式,但培訓它們很耗時。 GPU 上變壓器的快速微調可以通過提供顯著的加速而使許多應用受益。 RAPIDS cuML SVM 也可以作為經典 MLP 頭的替代品,因為它速度更快、精度更高。
GPU 加速為 SVM 等經典 ML 模型注入了新的能量。使用 RAPIDS ,可以將兩個世界中最好的結合起來:經典的機器學習( ML )模型和尖端的深度學習( DL )模型。在里面 RAPIDS cuML ,你會發現更多閃電般快速且易于使用的型號。
后記
在撰寫和編輯本文時, PetFinder.my 掌門人競賽 得出結論。 NVIDIA KGMON Gilberto Titericz 通過使用 RAPIDS 支持向量機獲得第一名。他成功的解決方案是集中變壓器和其他深層 CNN 的嵌入,并使用 RAPIDS SVM 作為回歸頭。
關于作者
Jiwei Liu 是 NVIDIA 的數據科學家,致力于 NVIDIA 人工智能基礎設施,包括 RAPIDS 數據科學框架。
Chris Deotte 是 NVIDIA 的高級數據科學家。克里斯有博士學位。在計算科學和數學中,有一篇關于優化并行處理的論文。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5597瀏覽量
109785 -
gpu
+關注
關注
28文章
5196瀏覽量
135506 -
人工智能
+關注
關注
1817文章
50102瀏覽量
265514
發布評論請先 登錄
Transformer 入門:從零理解 AI 大模型的核心原理
Transformer如何讓自動駕駛大模型獲得思考能力?
機器學習和深度學習中需避免的 7 個常見錯誤與局限性

穿孔機頂頭檢測儀 機器視覺深度學習
Transformer如何讓自動駕駛變得更聰明?
Vishay Sfernice TS7密封型表面貼裝微調電位器技術解析
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+第二章 實現深度學習AI芯片的創新方法與架構
NVIDIA RAPIDS 25.06版本新增多項功能
自動駕駛中Transformer大模型會取代深度學習嗎?

FPGA在機器學習中的具體應用
明晚開播 |數據智能系列講座第7期:面向高泛化能力的視覺感知系統空間建模與微調學習

Transformer架構中編碼器的工作流程

Transformer架構概述

直播預約 |數據智能系列講座第7期:面向高泛化能力的視覺感知系統空間建模與微調學習



 工商網監
工商網監
評論