") 一款A(yù)I模型Foley Music,它可以根據(jù)演奏手勢完美還原樂曲原聲!
一款A(yù)I模型Foley Music,它可以根據(jù)演奏手勢完美還原樂曲原聲!

不會樂器也可以玩的很嗨 ”
會玩樂器的人在生活中簡直自帶光環(huán)!
不過,學(xué)會一門樂器也真的很難,多少人陷入過從入門到放棄的死循環(huán)。
但是,不會玩樂器,就真的不能演奏出好聽的音樂了嗎?
最近,麻省理工(MIT)聯(lián)合沃森人工智能實驗室(MIT-IBM Watson AI Lab)共同開發(fā)出了一款A(yù)I模型Foley Music,它可以根據(jù)演奏手勢完美還原樂曲原聲!
而且還是不分樂器的那種,小提琴、鋼琴、尤克里里、吉他,統(tǒng)統(tǒng)都可以。
只要拿起樂器,就是一場專業(yè)演奏會!如果喜歡不同音調(diào),還可以對音樂風(fēng)格進(jìn)行編輯,A調(diào)、F調(diào)、G調(diào)均可。
這項名為《Foley Music:Learning to Generate Music from Videos》的技術(shù)論文已被ECCV 2020收錄。
接下來,我們看看AI模型是如何還原音樂的?
1
會玩多種樂器的Foley Music
如同為一段舞蹈配樂需要了解肢體動作、舞蹈風(fēng)格一樣,為樂器演奏者配樂,同樣需要知道其手勢、動作以及所用樂器。
如果給定一段演奏視頻,AI會自動鎖定目標(biāo)對象的身體關(guān)鍵點(Body Keypoints),以及演奏的樂器和聲音。
身體關(guān)鍵點:由AI系統(tǒng)中的視覺感知模塊(Visual Perception Model)來完成。它會通過身體姿勢和手勢的兩項指標(biāo)來反饋。一般身體會提取25個關(guān)2D點,手指提起21個2D點。
樂器聲音提取:采用音頻表征模塊(Audio Representation Model),該模塊研究人員提出了一種樂器數(shù)字化接口(Musical Instrument Digital Interface,簡稱MIDI)的音頻表征形式。它是Foley Music區(qū)別于其他模型的關(guān)鍵。
研究人員介紹,對于一個6秒中的演奏視頻,通常會生成大約500個MIDI事件,這些MIDI事件可以輕松導(dǎo)入到標(biāo)準(zhǔn)音樂合成器以生成音樂波形。
在完成信息提取和處理后,接下來,視-聽模塊(Visual-Audio Model)將整合所有信息并轉(zhuǎn)化,生成最終相匹配的音樂。
我們先來看一下它完整架構(gòu)圖:主要由視覺編碼,MIDI解碼和MIDI波形圖輸出三個部分構(gòu)成。
視覺編碼:將視覺信息進(jìn)行編碼化處理,并傳遞給轉(zhuǎn)換器MIDI解碼器。從視頻幀中提取關(guān)鍵坐標(biāo)點,使用GCN(Graph-CNN)捕獲人體動態(tài)隨時間變化產(chǎn)生的潛在表示。
MIDI解碼器:通過Graph-Transfomers完成人體姿態(tài)特征和MIDI事件之間的相關(guān)性進(jìn)行建模。Transfomers是基于編解碼器的自回歸生成模型,主要用于機器翻譯。在這里,它可以根據(jù)人體特征準(zhǔn)確的預(yù)測MIDI事件的序列。
MIDI輸出:使用標(biāo)準(zhǔn)音頻合成器將MIDI事件轉(zhuǎn)換為最終的波形。
2
實驗結(jié)果
研究人員證實Foley Music遠(yuǎn)優(yōu)于現(xiàn)有其他模型。在對比試驗中,他們采用了三種數(shù)據(jù)集對Foley Music進(jìn)行了訓(xùn)練,并選擇了9中樂器,與其它GAN-based、SampleRNN和WaveNet三種模型進(jìn)行了對比評估。
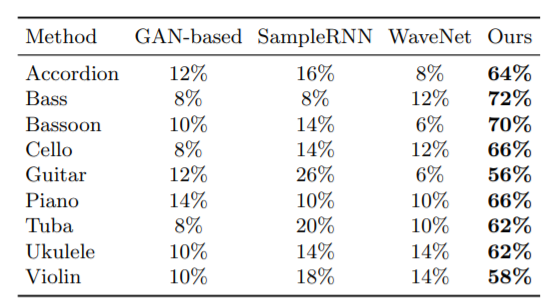
其中,數(shù)據(jù)集分別為AtinPiano、MUSIC及URMP,涵蓋了超過11個類別的大約1000個高質(zhì)量的音樂演奏視頻。樂器則為風(fēng)琴,貝斯,巴松管,大提琴,吉他,鋼琴,大號,夏威夷四弦琴和小提琴,其視頻長度均為6秒。以下為定量評估結(jié)果:
可見,F(xiàn)oley Music模型在貝斯(Bass)樂器演奏的預(yù)測性能最高達(dá)到了72%,而其他模型最高僅為8%。
另外,從以下四個指標(biāo)來看,結(jié)果更為突出:
正確性:生成的歌曲與視頻內(nèi)容之間的相關(guān)性。
噪音:音樂噪音最小。
同步性:歌曲在時間上與視頻內(nèi)容最一致。
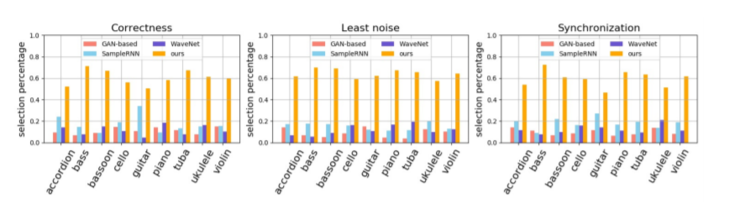
黃色為Foley Music模型,它在各項指標(biāo)上的性能表現(xiàn)遠(yuǎn)遠(yuǎn)超過了其他模型,在正確性、噪音和同步性三項指標(biāo)上最高均超過了0.6,其他最高不足0.4,且9種樂器均是如此。
另外,研究人員還發(fā)現(xiàn),與其他基準(zhǔn)系統(tǒng)相比,MIDI事件有助于改善聲音質(zhì)量,語義對齊和時間同步。
說明
GAN模型:它以人體特征為輸入,通過鑒別其判定其姿態(tài)特征所產(chǎn)生的頻譜圖是真或是假,經(jīng)過反復(fù)訓(xùn)練后,通過傅立葉逆變換將頻譜圖轉(zhuǎn)換為音頻波形。
SampleRNN:是無條件的端到端的神經(jīng)音頻生成模型,它相較于WaveNet結(jié)構(gòu)更簡單,在樣本級層面生成語音要更快。
WaveNet:是谷歌Deepmind推出一款語音生成模型,在text-to-speech和語音生成方面表現(xiàn)很好。
另外,該模型的優(yōu)勢還在于它的可擴(kuò)展性。MIDI表示是完全可解釋和透明的,因此可以對預(yù)測的MIDI序列進(jìn)行編輯,以生成AGF調(diào)不同風(fēng)格音樂。如果使用波形或者頻譜圖作為音頻表示形式的模型,這個功能是不可實現(xiàn)的。
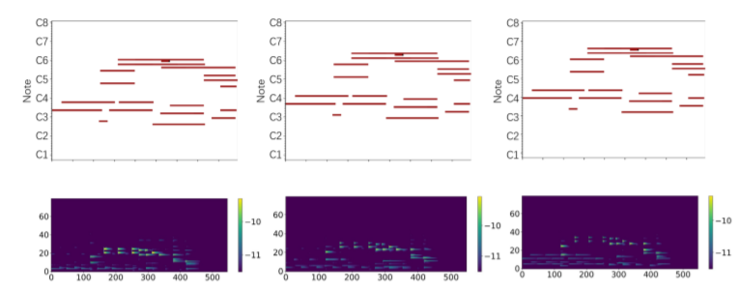
最后研究人員在論文中表明,此項研究通過人體關(guān)鍵點和MIDI表示很好地建立視覺和音樂信號之間的相關(guān)性,實現(xiàn)了音樂風(fēng)格的可拓展性。為當(dāng)前研究視頻和音樂聯(lián)系拓展出了一種更好的研究路徑。
-
AI
+關(guān)注
關(guān)注
91文章
39820瀏覽量
301500 -
人工智能
+關(guān)注
關(guān)注
1817文章
50102瀏覽量
265523 -
模型
+關(guān)注
關(guān)注
1文章
3755瀏覽量
52124
原文標(biāo)題:只看手勢動作,就能完美復(fù)現(xiàn)音樂,MIT聯(lián)合沃森實驗室團(tuán)隊推出最新AI,多種高難度樂器信手拈來!
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
大模型 ai coding 比較
使用NORDIC AI的好處
小新AI語音互動禮盒上線啦!正版IP原聲對話!啟明云端樂鑫代理

靈動微電子最新最火熱的一款芯片推薦
【飛凌OK-MX9596-C開發(fā)板試用】②體驗WIFI、藍(lán)牙、音頻、視頻,為AI應(yīng)用打下基礎(chǔ)
【技術(shù)討論】智能戒指手勢交互:如何優(yōu)化PCBA成本與實現(xiàn)<20ms低延遲?
傳統(tǒng)工業(yè)AP搞不定的PROFINET實時傳輸,為什么它可以?

OpenAI開源模型登陸IBM watsonx.ai開發(fā)平臺
新品上線|Maix4-HAT 大模型 AI 加速套件 ,一鍵解鎖樹莓派多模態(tài) AI 力量!

AlphaEvolve:一款基于Gemini的編程Agent,用于設(shè)計高級算法
首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
如何基于Android 14在i.MX95 EVK上運行Deepseek-R1-1.5B和性能
AI眼鏡大模型激戰(zhàn):多大模型協(xié)同、交互時延低至1.3S



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論