") 對象存儲適合AI和機器學習工作負載的三個原因
對象存儲適合AI和機器學習工作負載的三個原因

各種各樣的企業(yè)在加快AI和機器學習項目,但要真正發(fā)揮潛力,需要克服重大的技術(shù)障礙。雖然計算基礎架構(gòu)常常是關(guān)注的重點,但存儲同樣重要。這三個主要的原因表明了為什么對象存儲(而不是文件存儲或塊存儲)特別適合AI和機器學習工作負載:
1. 可擴展性——有龐大且多樣的數(shù)據(jù)源可供學習時,AI和機器學習最有效。數(shù)據(jù)科學家利用這些豐富的數(shù)據(jù)來訓練領域模型。在“大數(shù)據(jù)的五個V”(容量、種類、速度、準確性和價值)中,前兩個(容量和種類)最重要。簡而言之,AI和機器學習依賴大量多樣化的數(shù)據(jù)(圖像、文本、結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù)),構(gòu)建有用的模型、提供準確的結(jié)果并最終提供業(yè)務價值。
對象存儲是最具擴展性的存儲架構(gòu),特別適合支持AI和機器學習所需的大量數(shù)據(jù)。對象存儲旨在通過橫向擴展方法支持無限增長,使企業(yè)組織能夠通過隨時隨地添加節(jié)點來擴大部署范圍。由于對象存儲使用單個全局命名空間,也可以同時跨多個地方進行這種擴展。另一方面,文件和塊系統(tǒng)通常采用縱向擴展方法。這意味著這種平臺通過為單個節(jié)點添加更多計算資源實現(xiàn)縱向擴展,這種方法最終受到限制。它們無法通過部署額外節(jié)點來增加計算資源以高效地橫向擴展。
2. API——健壯靈活的數(shù)據(jù)API對于AI和機器學習很重要,如前所述,AI和機器學習使用多種類型的數(shù)據(jù)。存儲平臺需要支持API以容納各種數(shù)據(jù)。此外,AI和機器學習方面的創(chuàng)新日益在公共云上完成,但是仍有相當一部分的AI和機器學習在本地或私有云中進行,這取決于使用場合的具體情況(比如說,科學研究和醫(yī)療保健等領域的容量密集型工作負載往往最適合私有云)。這意味著企業(yè)需要在公共云和本地/私有云中都支持工作負載的存儲API。
文件和塊存儲平臺在它們支持的API方面受到限制,部分原因是它們是較舊的架構(gòu)。相比之下,對象存儲使用云端更高級的API,這種API旨在以應用程序為中心,并支持比文件和塊存儲更廣泛的API,包括版本控制、生命周期管理、加密、對象鎖定和元數(shù)據(jù)。此外,支持AI和機器學習使用場景的新對象存儲API(比如支持流數(shù)據(jù)和海量數(shù)據(jù)集的查詢)也有可能。
由于對象存儲API圍繞Amazon S3實現(xiàn)了標準化,更容易整合本地和公共云中的軟件。企業(yè)可以輕松地將部署的AI和機器學習從本地/私有云環(huán)境擴展到公共云,或者將云原生的AI和機器學習工作負載遷移到本地環(huán)境,功能不會減損。這種雙模式方法使企業(yè)能夠以合作、可互換的方式利用本地/私有云和公共云上的資源。
由于S3 API已成為對象存儲事實上的標準,許多軟件工具和庫都可以充分利用該API。這允許共享代碼、軟件和工具,促進AI/機器學習社區(qū)更快速的開發(fā)。例子包括流行的機器學習平臺,比如擁有內(nèi)置S3 API的TensorFlow和Apache Spark。
3.元數(shù)據(jù)——與API一樣,使用AI和機器學習的企業(yè)利用無限制、可自定義的元數(shù)據(jù)顯得至關(guān)重要。元數(shù)據(jù)就是關(guān)于數(shù)據(jù)的數(shù)據(jù)——從最基本的層面上講,某個數(shù)據(jù)何時在何地創(chuàng)建、創(chuàng)建者是誰。但是元數(shù)據(jù)可以描述更多信息:用戶可以創(chuàng)建任意的元數(shù)據(jù)標簽來描述他們需要的任何屬性。
數(shù)據(jù)科學家需要豐富的元數(shù)據(jù)來查找特定數(shù)據(jù)以構(gòu)建和使用AI和機器學習模型。隨著更多信息添加到數(shù)據(jù)中,元數(shù)據(jù)注釋便于逐步積累知識。
文件和塊存儲僅支持有限的元數(shù)據(jù),比如上述基本屬性。這在很大程度上歸結(jié)為可擴展性,因為文件和塊系統(tǒng)無力支持快速無縫的增長,如果存儲系統(tǒng)為依賴龐大數(shù)據(jù)集的AI和機器學習應用程序支持豐富的元數(shù)據(jù),自然會出現(xiàn)這種情況。然而,對象存儲支持無限制的、完全可自定義的元數(shù)據(jù),從而更容易找到用于AI和機器學習算法的數(shù)據(jù),并從中獲得更準確的信息。
以一家醫(yī)院針對X射線圖像使用圖像識別應用程序為例:有了元數(shù)據(jù),可以使用TensorFlow模型來分析添加到對象存儲系統(tǒng)的每個圖像,然后為每個圖像分配細化的元數(shù)據(jù)標簽(比如,傷病類型、基于骨骼大小或生長情況來判斷患者的年齡或性別)。然后可以針對該元數(shù)據(jù)訓練TensorFlow模型,并加以分析,對患者獲得新的寶貴信息(比如說,二三十歲的女性比五年前更容易患骨骼疾病)。
幾乎每家《財富》 500強公司都在大張旗鼓地搞AI和機器學習,可以想象這些技術(shù)在可預見的將來將是最重要的企業(yè)IT項目。然而,AI/機器學習項目要獲得回報,企業(yè)就要使用合適的存儲基礎架構(gòu)。由于可擴展性、支持各種API(尤其是S3)和豐富的元數(shù)據(jù),對象存儲可謂是AI和機器學習的最佳支柱。
-
存儲
+關(guān)注
關(guān)注
13文章
4791瀏覽量
90061
發(fā)布評論請先 登錄
定華雷達儀表學堂:不適合安裝雷達物位計的三個位置
三個經(jīng)典開關(guān)電源實際問題解析
MDD從工程故障看三極管三個極的設計誤區(qū)與失效案例

探索RISC-V在機器人領域的潛力
RK3576機器人核心:三屏異顯+八路攝像頭,重塑機器人交互與感知
未來工業(yè)AI發(fā)展的三個必然階段
Solidigm 成立AI中央實驗室,配備高性能、大密度存儲測試集群
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的未來:提升算力還是智力
醫(yī)療AI進化的三個關(guān)鍵技術(shù)路徑
【「零基礎開發(fā)AI Agent」閱讀體驗】+ 入門篇學習
【「零基礎開發(fā)AI Agent」閱讀體驗】+初品Agent
NanoEdge AI Studio 面向STM32開發(fā)人員機器學習(ML)技術(shù)
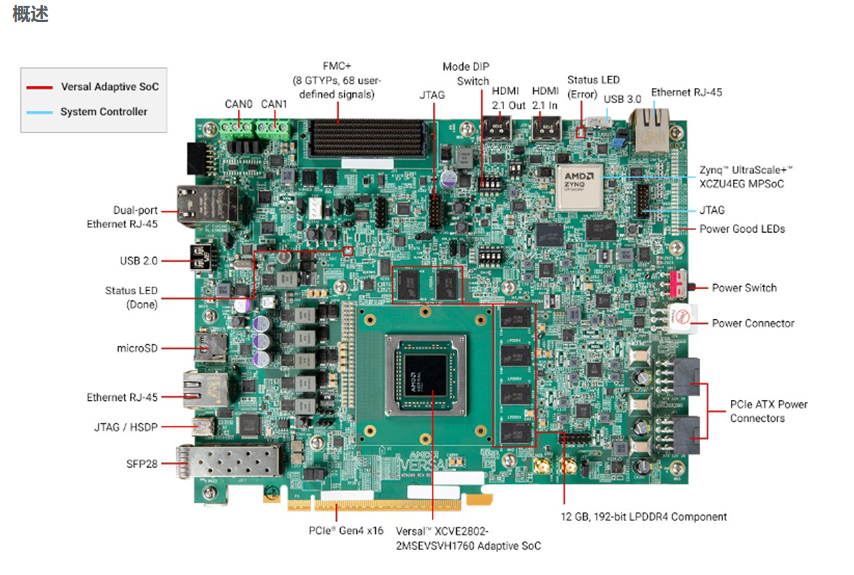
面向AI與機器學習應用的開發(fā)平臺 AMD/Xilinx Versal? AI Edge VEK280



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論